
Avec la super initiative de GLMF, vous voilà avec quelques 550 articles sur un CDROM. Voilà une petite astuce pour les exploiter au mieux 😉

A l’ouverture du CD, j’ai été un peu déçu de ne pas trouver un sommaire pour exploiter cette mine d’informations. Qu’à cela ne tienne, un petit coup de PERL et nous voilà avec un apercu HTML de la première page des articles. Le script calcule le nombre de pages de l’article grâce à l’information contenue dans le nom du fichier et le compare avec le nombre de pages du PDF afin de déduire s’il s’agit d’un fichier avec un copyright normal ( 1 page au début ) ou avec une licence Creative commons (2 pages au début et 2 à la fin). Le script génère alors un aperçu PNG de la 1° page de l’article qu’il insère dans une page HTML.
voilà les actions à faire pour mettre en oeuvre le script. Les pdf sont copiés sur le disque dur pour plus de confort. (450Mo)
mkdir -p GLMF/PDF
cd GLMF
wget https://www.equinoxefr.org/public/build_index.pl
sudo apt-get install libpdf-api2-perl imagemagick
cd PDF
find /media/cdrom/ -iname "*.pdf" -exec cp {} ./ \;
cd ..
./build_index.pl
reset
On aurait pu aussi supprimer les pages « gênantes », ce que j’aurais fait sans scrupule s’il s’était agit d’une pub et non d’une licence (Cf GLMF N°97 P82) . On aurait juste aimé que ces pages soient en fin de fichier et non au début afin de ne pas perturber les aperçus de fichiers.
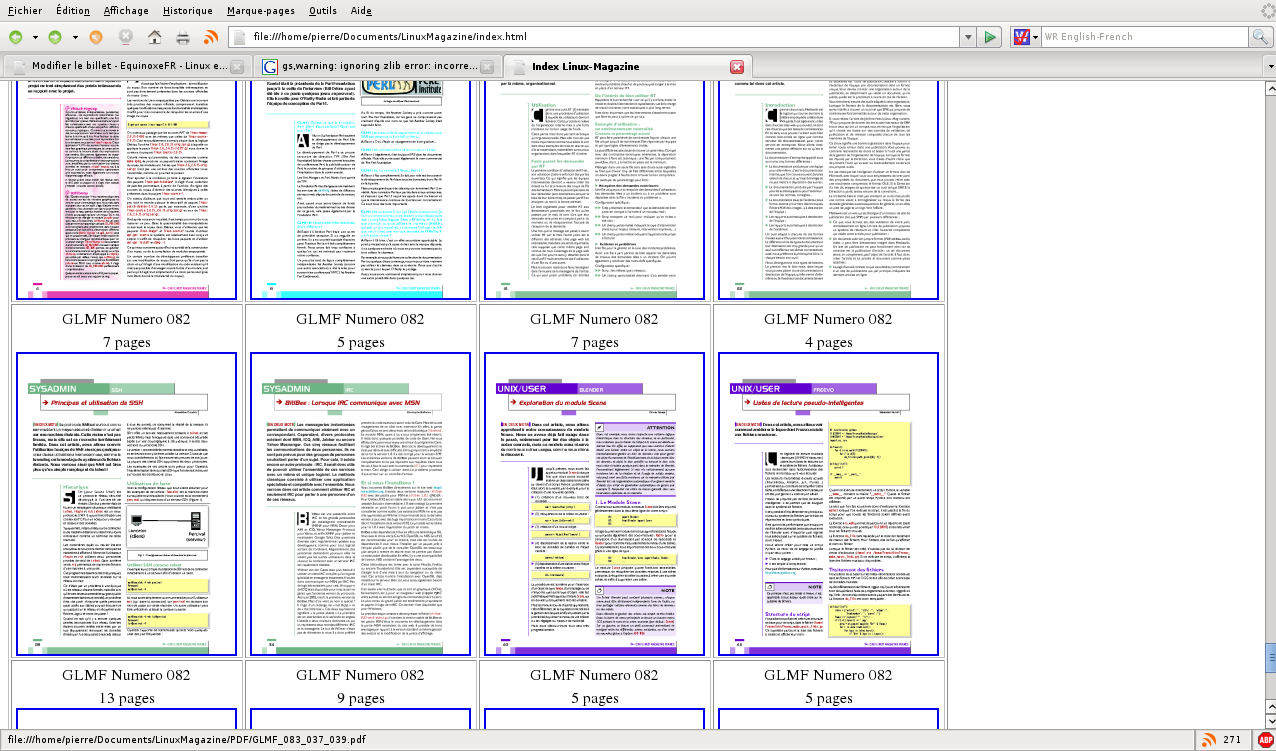
Voilà le script, fait à la « vas vite » mais qui marche sauf pour quelques PDF qui semblent altérés (un petit bug dans ghostscript entraine un affichage tout pourri dans le terminal d’où est lancé le script. heureusement un coup de reset remet tout en ordre).
#! /usr/bin/perl
use strict;
use PDF::API2;
my $PDF_PATH="./PDF";
mkdir("THUMBNAILS");
open(FD,">index.html");
my $nb=0;
opendir(DIR, "$PDF_PATH") || die "can't opendir ./PDF: $!";
my @files = grep { /\.pdf$/ } readdir(DIR);
closedir DIR;
print FD "<BODY><TITLE>Index Linux-Magazine</TITLE>\n";
print FD "<table border=1>\n";
foreach my $filename (sort(@files))
{
if ($filename !~ /GLMF_083_014_021/i)
{
my $pdf = PDF::API2->open("$PDF_PATH/$filename");
my $pdf_pages = $pdf->pages;
$pdf->end();
my ($mag_num,$page_start,$page_end) = ($filename =~ m/^GLMF_(\d+)_(\d+)_(\d+).pdf$/i);
my $art_pages = $page_end - $page_start;
my $copyright_pages = $pdf_pages - $art_pages;
if (!($nb % 4))
{
if ($nb)
{
print FD "</TR><TR>";
}
else
{
print FD "<TR>";
}
}
print "Convert $filename $pdf_pages pages in pdf, $art_pages in article diff:$copyright_pages\n";
print "Info: Mag n° $mag_num, article page $page_start to $page_end\n";
my ($base_name) = ( $filename =~ m/(.*?)\.pdf$/i );
if (! -f "./THUMBNAILS/COVER_${base_name}.png")
{
if ($copyright_pages >= 5)
{
`convert -scale 400x300 "${PDF_PATH}/${filename}\[2\]" ./THUMBNAILS/COVER_${base_name}.png`;
}
else
{
`convert -scale 400x300 "${PDF_PATH}/${filename}\[1\]" ./THUMBNAILS/COVER_${base_name}.png`;
}
}
print FD "<TD align=center>GLMF Numero $mag_num<br>$pdf_pages pages<br><a href=\"$PDF_PATH/$filename\"> <IMG src=\"./THUMBNAILS/COVER_${base_name}.png\"></a></TD>\n";
$nb++;
}
}
print FD "</table>\n";
print FD "</BODY>\n";
close(FD);
Génial ton script ! C’est la cerise sur le gateau !
🙂
ps :
_o\ \o/ /o_ Perl _o\ \o/ /o_
Oui, c’est bien pratique. Le problème c’est que certains PDF ne sont pas traités correctement…
Et il manque l’indexation sur mots clefs. Mais ça, je ne sais pas le faire rapidement 😉
AHHHHHH !!!
Merci pour ce script 😉
super, je me disais c’est ce qu’il manque, je cherche un peu sur le net, et voilà cette page ! vraiment génial.
Je me disais : on doit pouvoir aussi exporter le titre de l’article, au lieu de générer une image ? ça permettrait de faire une recherche texte sur la page html générée, quand on cherche un sujet particulier ?
mais je sais pas le faire ! 🙁
Pfiou, ça fait donc 6 mois que j’avais ça dans ma TODO liste !! Aujourd’hui c’est enfin fait, alors un grand merci à toi.