
Voici comment utiliser l’OCR (reconnaissance de caractères) avec Xsane sous Ubuntu hardy.

Il faut tout d’abord installer Xsane, imagemagick (avec synaptic ou apt-get) et tesseract. Pour installer ce dernier, il faut utiliser le tutoriel situé ici. Faites bien attention à suivre le tutoriel « Par les deb de « b52″ (32 et 64 bits) ».
Afin d’interfacer Xsane et tesseract, il faut un script. J’en ai trouvé un nommé xsane2tess mais il ne fonctionne pas chez moi. J’en ai donc créé un autre que vous pouvez installer comme ceci:
[code lang= »bash »]
cd /usr/bin
sudo wget https://www.equinoxefr.org/wp-content/uploads/2008/07/xsane2tess.pl
sudo chmod +x xsane2tess.pl
[/code]
Ensuite lancez Xsane et allez dans Préférence / Configuration (ALT+s) pour entrer les options suivantes
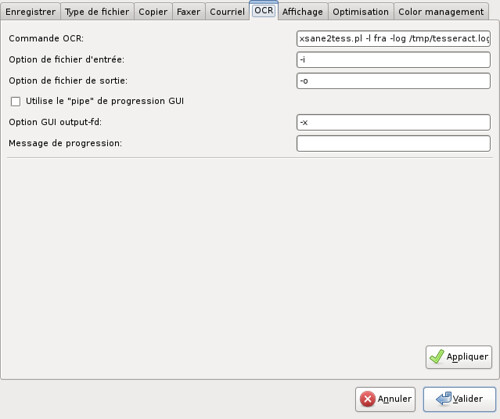
Après avoir validé les bonnes options, il faut mettre les paramètres Sane comme suit:
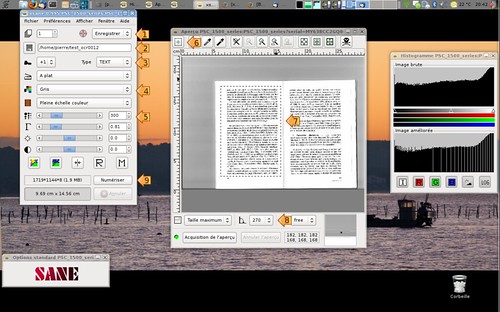
- Mode enregistrer
- Nom de fichier sans extension
- Type de fichier TXT
- Mode de scan: GRIS
- Résolution: 300 dpi donne de bons résultats
- Sélectionnez la zone de texte
- La sélection
- Effectuez une rotation si nécessaire
- Lancez le scan
Voilà, vous avez maintenant un beau fichier TXT qu’il vous faudra vérifier avec openoffice et son correcteur d’orthographe par exemple.
Les résultat sont assez étonnants, j’avais essayé GOCR il y a quelques temps mais j’en étais très déçu. Là, il y a avec tesseract, une véritable alternative aux outils propriétaires.
Bonne OCR 😉



