
Voici comment utiliser l’OCR (reconnaissance de caractères) avec Xsane sous Ubuntu hardy.

Il faut tout d’abord installer Xsane, imagemagick (avec synaptic ou apt-get) et tesseract. Pour installer ce dernier, il faut utiliser le tutoriel situé ici. Faites bien attention à suivre le tutoriel « Par les deb de « b52″ (32 et 64 bits) ».
Afin d’interfacer Xsane et tesseract, il faut un script. J’en ai trouvé un nommé xsane2tess mais il ne fonctionne pas chez moi. J’en ai donc créé un autre que vous pouvez installer comme ceci:
[code lang= »bash »]
cd /usr/bin
sudo wget https://www.equinoxefr.org/wp-content/uploads/2008/07/xsane2tess.pl
sudo chmod +x xsane2tess.pl
[/code]
Ensuite lancez Xsane et allez dans Préférence / Configuration (ALT+s) pour entrer les options suivantes
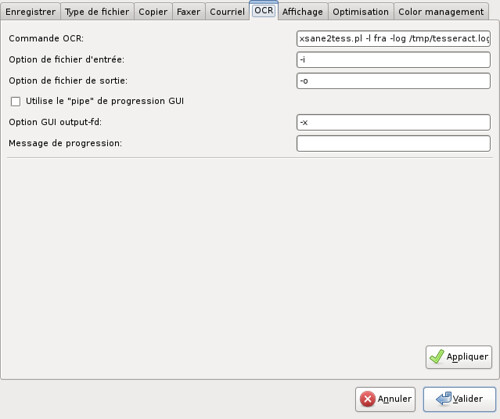
Après avoir validé les bonnes options, il faut mettre les paramètres Sane comme suit:
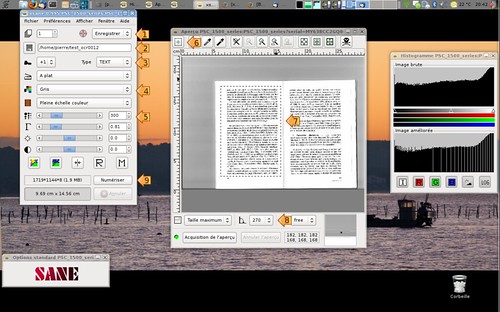
- Mode enregistrer
- Nom de fichier sans extension
- Type de fichier TXT
- Mode de scan: GRIS
- Résolution: 300 dpi donne de bons résultats
- Sélectionnez la zone de texte
- La sélection
- Effectuez une rotation si nécessaire
- Lancez le scan
Voilà, vous avez maintenant un beau fichier TXT qu’il vous faudra vérifier avec openoffice et son correcteur d’orthographe par exemple.
Les résultat sont assez étonnants, j’avais essayé GOCR il y a quelques temps mais j’en étais très déçu. Là, il y a avec tesseract, une véritable alternative aux outils propriétaires.
Bonne OCR 😉
J’utilisais auparavant gscan2pdf, mais cette solution semble plus légère.
Merci pour l’info et le fichier perl 😉
Bonjour,
et mille fois merci pour ce tuto trés explicite qui fonctionne à merveille, sans difficultés.
Bonjour,
Je suis sur Debian sarge. Les paquets tesseract, imagemagick sont installés. Xsane fonctionne. J’ai suivi vos instructions à part le rep d’install /usr/local/bin.
Mais aucun fichier txt ne sort. J’ai pourtant vérifié le rep de sortie. Existe-t-il un moyen de voir si il y a des erreurs à la reconnaissance? Avec gocr j’avais une sortie, mais inexploitable.
Merci
Bonjour @Sylvain F,
Avez vous installé tesseract « debian » ou comme moi la version « b52 » ? Chez moi je n’ai pas de résultat avec la version Ubuntu, ça ne marche qu’en installant la version B52. Sinon le log par défaut est dans /tmp/tesseract.log
Merci pour ces précisions.
1. J’ai pu installer le deb b52 avec dpkg (j’aurais préféré utiliser synaptic car je ne suis pas un expert et donc pas à l’aise avec les pbs de dépendances).
2. J’ai lancé xsane à partir de la ligne de commande. J’ai vu ça sur les forums pour visualiser les messages d’erreur :
Unknown option: x
tesseract: /usr/lib/libstdc++.so.6: version `GLIBCXX_3.4.9′ not found (required by tesseract)
je n’arrive pas à trouver de sol sur les forums. Help!
bonjour j’essaie d’utiliser votre méthode mais je n’y arrive pas je suis débutante je précise, voila le message que j’obtiens :
Erreur de processus enfant
failed to execute ocr command:
xsane 2tess pl-l fra-log/tmp/tesseract log:
aucun fichier ou dossier de ce type
pouvez vous m’aider
merci d’avance
@nemea, a priori c’est peut être du à l’espace entre xsane et 2tess.
Normalement la commande est:
xsane2tess.pl -l fra -log /tmp/tesseract.log
Je précise, avec Ubuntu intrepid, il n’y a pas besoin des dépots b52. Un simple « apt-get install tesseract tesseract-fra » est suffisant.
merci je viens d’essayer et voila la réponse en console
E: Impossible d’ouvrir le fichier verrou /var/lib/dpkg/lock – open (13 Permission non accordée)
E: Unable to lock the administration directory (/var/lib/dpkg/), are you root?
je me bats avec cela depuis plusieurs jours c’est frustrant
d’autant plus que je ne parle pas anglais
je vais tout réinstaller mais j’aimerais savoir ce que veut dire le message ci dessus
merci d’avance
Némea
@nemea, tu n’as pas les droits d’installer tesseract. Pour le faire, il faut être super utilisateur. Essaye ça:
« sudo apt-get install tesseract tesseract-fra »
bonsoir
merci encore je ne sais pas comment j’ai fait mais cela fonctionne sur un petit morceau de texte je crois que c’est un coup de chance car vraiment je cafouille , mais ton aide a été précieuse ceci dit l’ocr n’est pas mal je vais continuer mes essais,à suivre certainemen
merci à toi
néméa
@nemea, bon courage. Je trouve les résultats de l’ocr plutôt bon, excepté pour la mise en page.
Salut
Ça marche bien sous Debian Sid avec les paquets Debian. Et c’est vrai que comparé au charabia de gocr, cela devient utilisable.
Salut EquinoxeFR,
Ici Sorbus, du forum (et de la doc) Ubuntu. Merci pour ce tuto qui complète la diffusion de bonnes infos au sujet de l’OCR sous Linux.
Ce petit message pour plusieurs choses :
– nous avons remarqué, sur le forum Ubuntu, qu’une espace mal placée dans la configuration de xsane (avant le « -i », ou après le « -l fra » empêche le fonctionnement correct de xsane2tess.
cf. ici : http://forum.ubuntu-fr.org/viewtopic.php?pid=2535312#p2535312
– quel problème avais-tu rencontré avec le script xsane2tess de la doc Ubuntu ? (n’était-ce pas aussi ce problème d’espace ?)
– quelles sont les modifs de ton fichier xsane2tess.pl par rapport au script xsane2tess de la doc Ubuntu ? (je vois que la commande OCR indiquée dans la configuration de xsane comporte en plus un « -log » et un chemin commençant par le répertoire tmp.)
En OCR, sous Linux, il nous faudrait maintenant commencer à tester Ocropus… Que les premiers qui testeront tiennent au courant les autres 😉
A bientôt !
Salut, merci mille fois pour le tuyau et le script 🙂
Bonne continuation
Magnifique OCR réalisée sous Ubuntu 10.04.
Une seule faute relevée sur 21 lignes de texte ( « partemires » au lieu de « partenaires » ) mais, précision, cette ligne est écrite en bleu marine.
Grand MERCI pour ce tuto
@lain
Merci beaucoup, je viens de tester l’installation faite selon vos indications
sur mon ordinateur sous debian stable.
J’ai utilisé les paquets tesseract-ocr et tesseract-ocr-fra des dépôts debian.
çà marche très bien!
cmm
J’avais toujours utilisé xsane2tess sans problème avec Ubuntu (en scannant en trait à 300 dpi). Ce soir, je découvre qu’il ne fonctionne plus. C’est sans doute la première fois que j’ai essayé depuis le passage à Ubuntu 10.10. Erreur (que je ne comprends pas assez pour avoir le courage d’essayer de corriger xsane2tess ou le reste) :
/home/mic/tmp/xsane-conversion-plustek:libusb:002:002.tif: Not a TIFF or MDI file, bad magic number 13136 (0x3350).tesseract:Error:Read of file failed:/home/mic/tmp/xsane-conversion-plustek:libusb:002:002.tif
/usr/bin/xsane2tess: line 78: 4799 Erreur de segmentation tesseract "$TIF_FILE" "$TXT_FILE" -l "$TES_LANG" 1>&2
cat: /home/mic/tmp/xsane-conversion-plustek:libusb:002:002.txt: Aucun fichier ou dossier de ce type
rm: ne peut enlever `/home/mic/tmp/xsane-conversion-plustek:libusb:002:002.txt': Aucun fichier ou dossier de ce type
Par contre, ça marche avec xsane2tess.pl en gris à 300 dpi. Le script écrit le log dans /tmp par défaut. Il n’est donc pas indispensable de l’écrire dans la commande.
J’ai le même souci que Dominque:
Not a TIFF or MDI file, bad magic number 13136 (0x3350)le passage de 10.04 à 10.10 semble avoir détraqué le fonctionnement de xsane2tess. En revanche, tesseract fonctionne bien en ligne de commande, à partir d’un fichier .tif : c’est donc bien le script xsane2tess qui est en cause. Je l’ai regardé, d’un oeil peu expert, mais je ne vois rien a priori qui puisse poser problème. Toute aide sera la bienvenue!Je reviens à la charge, pour confirmer, comme Dominique, que le fichier .pl fonctionne sous 10.10, en 300, 600 ou 1200 dpi. Merci, Equinoxe!
Bonjour,
Merci pour vos infos. Je vais essayer cet OCR.
Pouvez-vous donner des exemples d’utilisation à partir d’un fichier image (*.tif par exemple) car xsane ne sait évidemment pas faire (sans scanner branché il ne s’ouvre même pas.) ?
Quels sont les types de fichiers image qui fonctionnent avec cette solution ?
S’il vous plaît, donnez les détails (codes complets) car je ne suis pas spécialiste !
D’avance MERCI !
Bonjour,
Pour Croa, en consultant le manuel
man tesseracton voit que la commandetesseract inputfile.tif outputfiledevrait suffire (tesseract rajoute le suffixe .txt sans que vous ayez besoin de préciser). Vous pouvez également préciser la langue (à condition d’avoir téléchargé le fichier qui y correspond) avec, par exemple,tesseract inputfile.tif outputfile -l fra(Vous pouvez consulter le code complet du fichier laissé par Equinoxe ici http://www.equinoxefr.org/wp-content/uploads/2008/07/xsane2tess.pl en ouvrant le fichier avec un éditeur de texte. Mais en ce qui concerne tesseract seul, le code donné ci-dessus suffira!)
J’ai fait la même configuration de Xsane sous Mandriva après chargement banal de tesseract avec le gestionnaire de logiciel (graphique) et tout fonctionne à merveille.
J’ai scanné un vieux livre jauni de 1920 avec des résultats tout à fait exploitables, et d’autres scans sur des sorties d’imprimante, qui ne nécessitent eux quasiment aucune retouche.
Vraiment très bien!
LM.
Bonjour,
Je suis sous Debian Squeeze 6.0.4.
Je voudrais utiliser votre méthode pour scanner des extraits de livres. J’ai suivi votre Tuto, tout semble parfaitement fonctionner à un détail prêt: je ne trouve pas où récupérer le fichier TXT sauvegardé pour le reprendre avec Open-Office ???
Dans le 2 du Tuto j’ai ça:
/home/escienca/Bureau/scantest-0005
Cela ne semble pas se sauvegarder. J’ai fait un « rechercher » dans mon système, mais je ne trouve rien.
Merci de votre aide.
Bonsoir,
j’ai trouvé pour les sauvegardes. Dans le 2 du Tuto au lieu de:
/home/escienca/Bureau/scantest-0005
Je met juste le nom du fichier (exemple ici: scantest-0005), et il se sauvegarde dans mon navigateur de fichiers (la maison rouge pour Squeeze ^_^).
Mais j’ai un autre problème, quand j’ouvre le fichier TXT sauvegardé avec Open-Office, au lieu de me rendre un texte « classique » je me retrouve avec ça:
`SIIOQSUGUIQP 9.11EHb Q 9pUOII.I 9[ SUBp SBIQUUOPJOOD
Bp GUIQQSÃS Hp « lI0§1B]0.I » GIIII If} plI0dS3.I.X0i) Z]U9.I0″`[
Gp U0§]BUI.IO]SIIÉ.I1 BI §(9.I§BII!8BI1I[ Sdlllâl ap 9QUIIOp.I0·O°Z)
GUI! OBAB) SIIOQSIIBIIIEP 9.IZ}BIlb Q U9[pHZ)I\3 8l`)BdS9 IITI
GUIIIIOD ‘[9L\I.I0] 9IlA Gp 1}II[Od HB ‘p[sm0>[ugN Gp GPIIOUI 3[
xapxeâax quad ug ‘9}Q[dl1I0() qsa (zx) oame agâopauej
` ·§x —+— §.2· —+— Qxr : fr -4- nîzr + ;‘_.z·
lIOnEI`lbQ‘[ If! Z}II3III3Ilb!1II3p[ f}IIO}S[;|ES ‘sîlî œil! dz Gp
SGIIQSOHIOII SGJQBQUEI SUOQOIIOJ Sêp QIIOS ‘î$ HIZ S.IO[E
‘aug8g.10 ouxgm quelle (fa: ‘Éx « ,:v) uags2;>3.1eo saçuuopxooa
Gp QIIIQQSÃS TIHGAUOU III’! 9.IQ[lI.I9p 31193 SUB!) È],!l’1p0.l],U!
`(IO‘[ [S °]9]J9 IIE ‘(I-)UlI’3!p!]OI`l9) 3¥lb§]Ã[BIIB QQJQQUIOQQ
B[ Gp SIIOQSIIGILIQP S§O.I1 Q « 9i)BdS9‘[ » OQAB BOUEIQIHBSSSJ
9p\IOJ0.Id GIIU B SUO[S(I9IlI§[)~ 6.118111) « SPIIOHI J) 93
‘SUOQSIIGLLIQP 9.I]EI\b If!
« :—>pu0u1 » OI suep 9J]9‘] 9].108 9I1b[9I\b UG guapxap 9I’lb!S
H[ ‘SlIOQSII9U.I[p S§0.IÉ]. 9i)EdS9″[ SIIBD .l]U2(l9p HIl‘(I
‘« BPUOHI Hp 1II!0d » ]\I3lII9UQAî}··1I.I§0d GI 19 « 3[NIOHI 1
pqsmoxiugw xed çpdde 9;:3 e « :n « ’x ‘“:z: « a: « saguuopxooo z
S9] .1Bd CHJOQI) °SlI0§SlI9I1I§[) 9.I}BI’lb I1Il’\T\U§]lIO0 3″[
« gflî dx ‘ïflî 9I)EdS9″[) S9’§)UUOp.IOOI) Si-)[ Qïlb IIOÉBJ GIIIQUJ HI Gp
9.IIlZ[BII 8[ 9]) S[0[ S9] SIIÉP 9J1U3 ‘Z «SdII1î-)1» 9[ °§][A[1`B[9.I BI
lg! ‘DlSA)|NIMl I-IG SNOISNEIWICI EIILVHD V HGNOW 31
Aurais je omis un codage quelque part ?
Merci de votre aide…
Hmm, question bête, mais vous êtes sûr qu’il était dans le bon sens au départ, votre texte? Ca ressemble diablement à un travail d’OCR sur un texte scanné à l’envers…
Bonjour,
j’ai trouvé pourquoi les caractères étaient mal reconnus. Il s’agit de la taille. Dans la fenêtre de l’aperçu, il faut paramétrer les dimensions. La case se trouve sous l’aperçu à gauche. Pour scanner des pages de livres, je conseillent également de presser un peu dessus pendant l’acquisition, afin que la page sois bien collé sur la vitre du scanner. Ensuite, à quelques infimes détails prêts facilement corrigibles (par exemple les indices ou les exposants si vous scannez des pages de livres de sciences, ce qui est mon cas pour la cosmologie), le résultat est réellement bluffant ! Que de temps gagnés ! Merci pour ce tuto vraiment utile.
Bonjour,
le lien vers le téléchargement de Tesseract en .deb a changé, tout est ici:
http://freezone.linux59.info/download.php?lng=fr
Pour installer avec la (bonne) méthode de ici, je vous conseille tesseract_2.04-1. Une fois installé avec Gdebi, il suffit de reprendre le tuto et de finir de tout installer. Chez moi ça marche.
Cordialement.
PS: je ne sais pas pourquoi la page du Forum Ubuntu a été modifié, je ne vois pas en quoi cette page était obsolète !!!
Super tuto encore valable aujourd’hui (12.04LTS)
Merci beaucoup!
Tesseract ne redresse pas les pages et le résultat baisse avec l’inclinaison des lignes. J’ai ajouté dans une version modifiée une commande deskew qui redresse la page (et remplace convert du même coup).
Sur Ubuntu 20.04, après avoir longtemps galéré, j’ai trouvé ce script qui fonctionne. Merci infiniment.
Content de voir qu’un article écrit en 2008 n’est toujours pas obsolète 😉