Depuis pas mal de temps, j’accumule les photos numériques comme beaucoup d’entre vous. J’en suis à 14000 photos en 8 ans, mon système de classement en dehors de tout logiciel de gestion de photos, se base sur une arborescence chronologique.
On voit bien les limites de ce système, il manque une gestion efficace des tags. Après avoir testé divers produits: digikam, picasa, jbrout, mon intérêt s’est porté sur F-spot. Étant utilisateur de Gnome, c’est celui qui semble le mieux intégré à l’environnement. Les fonctionnalités sont intéressantes, mais il manque cruellement d’une fonctionnalité d’import en masse qui marche (l’import prévu dans f-spot ne permet pas de dépasser le millier de photos sous peine de saturer toute la ram) et qui ne perturbe pas mon classement en dossiers. Après une petite analyse de leur système de stockage des metadata (sqlite3), voici un petit script perl vite fait qui permet d’importer en masse sans déplacer vos photos.
[code lang= »bash »]
sudo apt-get install libdbd-sqlite3-perl libdate-manip-perl libdbi-perl libimage-exiftool-perl
wget https://www.equinoxefr.org/wp-content/uploads/2008/07/import2fspot.pl
chmod +x import2fspot.pl
[/code]
Lancez maintenant F-spot une première fois si ce n’est pas déjà fait afin qu’il créé une base de donnée vierge.
Quittez F-spot,ensuite, dans un terminal, lancez l’import.
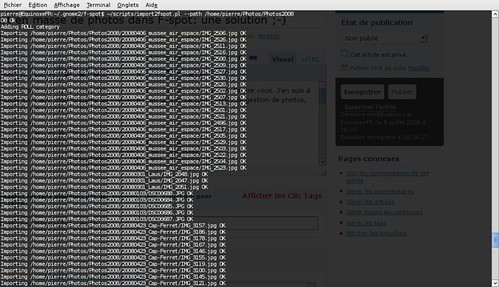
Quelques minutes plus tard, vous voilà avec toutes vos photos importées dans F-spot. Voilà les temps relevés avec la commande time pour importer 13800 photos:
real 17m28.227s
user 12m12.038s
sys 0m23.117s
Les photos sont toutes taggées avec le nom du répertoire dans lequel elles se trouvent pour ne pas perturber le classement par répertoire. Normalement, les photos déjà importées ne sont pas réimportées.
Je n’ai pas importé les éventuels tags exifs existants dans les photos (je n’en ai pas) mais ce n’est pas très difficile à faire. Si jamais quelqu’un s’y intéresse, merci de m’envoyer le code, je publierai les modifs ici 😉
Rémy vous propose une nouvelle version disponible ici http://zouf.org/public/import2fspot.pl Merci 🙂